on
代码之上:我们落地 GraphQL 背后的故事
GraphQL 经常被打上“好东西,但是难以落地”的标签,很多尝试 GraphQL 的团队也经历了“从入门到放弃”的痛苦。而我们能够在过去一年多的时间里让 GraphQL 在项目中平稳落地,其背后是一个技术决策、工程管理和代码相结合的有趣故事。
在这篇文章中我会按照故事的时间顺序讲述:
- 启蒙期:为什么我们需要 GraphQL
- 原型期:熟悉 GraphQL,熟悉社区
- 蜜月期:在内部系统中应用 GraphQL 并快速收获成果
- 接入期:做个浏览器内运行的 GraphQL 网关
- 痛点期:前、后端同时遭遇挫折
- 落地期:把握机会,真正的 GraphQL
为什么我们需要 GraphQL
在谈“为什么”之前,首先说说“我们”是谁。
我们是 SmartX 的前端团队。相信和我们一样,很多公司内引入 GraphQL 都是由前端团队发起的。不同之处在于从最开始我们就不希望给后端团队带来任何额外工作量,下文中我们会逐步讲述我们如何做到这一点,但毫无疑问这是我们最终成功的重要基础。
再说我们“为什么需要”。2019 年 1 月,GraphQL 第一次在组内讨论中被写到了白板上,当时组内没有任何一个人对 GraphQL 有实质性的了解,提起只是因为我们想要解决前端项目中复杂的数据拼接问题,而 GraphQL 在我们的印象中是一个擅长数据拼接的技术方案。
在我们的前端项目中数据拼接有多复杂?可以从以下这个不完全真实(但复杂程度是接近的)的示意图里感受一下:
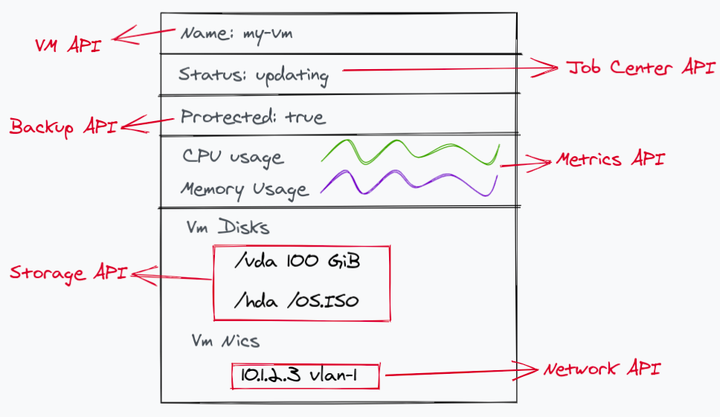
一个看起来并不复杂的 UI 内使用了多个服务的 API,并且这些 API 可能由多个组开发,在格式、语义、异常处理上都有一定的差异性,因此一个“可以拼接数据、按需获取的规范”就成为了我们最初的诉求。
不止拼接,GraphQL 的工程价值
在后续各个阶段的实践中,我们很快意识到 GraphQL 提供的远不止减少网络请求数量、按需获取数据这么简单,它还为我们带来更多工程价值。
强类型接口定义避免前后端不一致
在 GraphQL 的规范中,前后端都需要静态的声明接口和请求的结构。例如后端提供 User 接口,声明其中包含 name 和 email 两个字段。
如果前端对 User 发起请求,错误地请求了不存在的字段 age 字段,那么在静态阶段(编译、lint 等)我们就有能力发现这个错误。
同样地,如果后端在某一个版本中引入了一个 breaking change,将 email 字段重命名为 email_address,前端项目中使用了 User.email 的请求也可以在静态阶段发现问题,而不需要在运行时通过测试暴露。
虽然这些问题都可以通过人为的沟通、联调来避免,但效率和可靠程度显然不是一个层次的。
另一方面,如果前端项目中使用了 Typescript 等强类型语言,也可以通过工具链从 GraphQL 接口定义中生成 Typescript 类型声明,让整个数据请求的链路上处处都是类型安全的,并且没有额外的维护成本。
响应式的级联缓存
UI 里的数据管理是一个更复杂的话题,值得一篇文章单独讨论。这里我尝试用一个简单的示例说明基于 GraphQL 为什么更容易实现一个好用的客户端缓存。
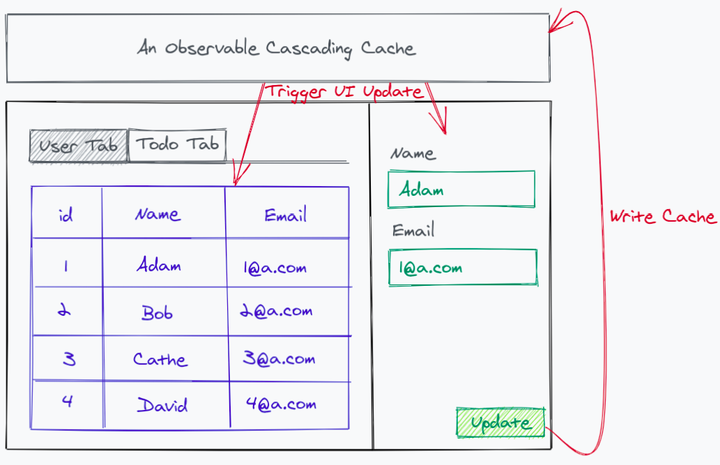
上图中有一个 Tab、一个 User 表格和一个 User 表单。如果从表单中修改了 Adam 的 Email 地址,我们期望通过 API 把最新的 Email 发给后端,并且把表格和表单中 Adam 的 Email 地址都显示为修改后的最新值。
如果我们希望 UI 的变化自动(而不是通过额外的业务逻辑)发生,就应该实现这样的一个缓存:
- 响应式。 缓存既要知道 Adam 的 Email 地址对应的是 id 为 1 的 User 这条数据,也要知道有一个表格和一个表单正在”依赖“这条数据。当数据发生变化时,缓存要”通知“这些依赖了对应数据的 UI 重新渲染一次,更新到最新状态。 当 UI 不再”依赖“这条数据时(例如通过 Tab 切换到了 Todo Tab,User 表格不再展示),该数据再发生变化时也不会再触发渲染。
- 级联 UI 对数据的使用可能来自不同的入口,例如获取所有 User 的 API、获取单个 User 的 API、获取一个 Todo 的创建者的 API。但不论入口来自哪里,缓存都能够通过 id 为 1 的 User 这条数据层层追溯,将它们关联在一起。
GraphQL 可以让这一切更容易发生,因为:
- 数据之间的关联关系在静态的 schema 中已经完整声明。
- 可以精确到字段级别的响应式。
好处都是前端的,工作量大部分是后端的
从上文的描述中可以看出,很多工程价值都在于前端可以基于 GraphQL 更好的组织代码,但要提供一个 GraphQL API 的主要工作量却在于后端。
我们很早就认清了这一事实,并且做出了一个判断:**GraphQL 对于网络请求的优化(数量、数据量)不是我们最看重的价值,我们可以在前端项目中实现一个运行在浏览器内的 GraphQL 网关,获得 GraphQL 带来的其它好处。**这样的方式不需要后端的配合就可以独立完成,并且可以在足够成熟后快速转化为一个独立的 NodeJS 服务,完整享受 GraphQL 的所有优点。
不过在这么做之前,我们还有很多调研工作需要完成。
快速取得成果
2019 年春节过后,我们正式开始了对 GraphQL 的调研工作。为了加速调研的过程,我们同时开展了两方面的工作:
- 熟悉 GraphQL 本身以及它的社区。
- 在严肃程度不那么高、但又有一定复杂度的项目中使用 GraphQL。
GraphQL 社区
尽管 GraphQL 最初是由 Facebook 开源的,但发展至今已经成为了典型的社区驱动项目。由社区主导的项目容易产生以下特点:
- 方向经常变化,每一小段时间就有新的明星项目产生,但也经常有项目停止维护甚至废弃。
- 对于一些长期存在的设计缺陷缺乏修复的动力,往往要在下一个大版本重构时才被解决。
为了在尽可能使用社区成果的同时避免“踩坑”,我们首先对各类项目及其维护者做了分类。从功能上分类,我们把这些项目分为 3 层:
- Spec 层面。GraphQL Spec 是核心的部分,与语言无关,描述的是 GraphQL 的标准行为。本身由 GraphQL Working Group 维护,每一到两年发布一个新版本。本身非常稳定,在考察其它项目时我们会以对 Spec 的实现程度作为重要的评判标准。
- 实现层面。目前很多编程语言都对 GraphQL Spec 进行了实现,JavaScript 对应的 graphql-js 是由官方维护的,目前也基本不存在替代品。
- 应用层面。和以上两个层面的稳定不同,社区在应用层面有层出不穷的项目,包含后端 server、前端 client、数据库 ORM 封装等很多方向。
- 工具链层面。同样有很多的项目,包含 lint、编译、测试各个方面。
在调研的过程中我们每接触到一个新的项目,就会将其放在对应的层面,和同层同功能的其它项目进行比较,在比较的过程中更容易找到每个项目的优势和不足。
另一方面我们对项目背后的维护者也做出了描述性的判断,以我们最终采用的项目对应维护者为例:
- Apollo 是社区中的重要成员,本身也有商业化的 GraphQL 产品。在应用层面和工具链层面都维护了很多项目,但是对于解决项目中长期存在的设计缺陷动力比较匮乏。
- Prisma 和 Apollo 类似,也有自己的商业化产品。相比之下 Prisma 更为激进,喜欢不断推出新的版本、项目来替代自己过去的项目。
- The Guild,由社区组织,非常活跃地维护了几个高质量的项目。
熟悉维护者的风格,阅读项目中长期存在的 issue,让我们提前了解到各个项目存在的“坑”和可能解决的时间点。再结合我们自己的接入计划,大大降低了后期实际使用时的风险。
在内部系统里练习
和很多公司一样,SmartX 也有一些内部系统的需求。这类系统大部分是 Web Service + Web UI 的形态,不涉及底层(虚拟化、分布式存储)的技术,所以交由前端组进行开发。
与产品主线相比,这些内部系统是验证新技术栈绝佳的试验田,因为它们:
- 交付周期更灵活,有一定的试错空间。
- 自动化测试较少,Code Review 更侧重整体设计,代码合入速度快。
- 不需要过多考虑升级、兼容性等问题。
- 有一定的业务逻辑,一些系统里业务逻辑甚至相当复杂,更容易验证技术栈在各种场景下的表现。
从 2019 年上半年开始,我们所有的内部系统都开始采用 GraphQL 作为 API 接口规范。其中最为突出的成果是我们用 1.5 个人力在 2 个月的时间里完成了售后系统的开发,不论在开发效率还是用户体验上都有令人满意的表现。
经过在内部系统里的实践,我们在 2019 年 6 月时做到了:
- 熟悉 GraphQL 社区的进展,从众多项目中挑选出了几个适用于我们使用场景的进行长期投入。
- 拥有两名非常熟悉 GraphQL 的组员。
Data Layer: 浏览器内的 GraphQL 网关
2019 年 5 月份,我们带着在内部系统中积累的经验回到产品主线的前端项目中,开始设计代号为 data layer 的纯前端 GraphQL 方案。
事实上 GraphQL Spec 从来没有限制 server 部分的运行环境,所以我们完全可以在浏览器内实现一个 GraphQL server 运行时。
GraphQL 的执行方式
以一段 GraphQL schema 为例:
# [] 代表数组,! 表示不能为 null
type Query {
users: [User!]!
}
type User {
name: String!
posts: [Post!]!
}
type Post {
title: String!
}
如果我们要查询所有用户的姓名以及每个人写的文章的标题,就可以发起一个这样的查询
query {
users {
name
posts {
title
}
}
}
按照 GraphQL spec 的要求,server 在处理这个查询时的顺序依次是:
- 以 query 作为入口,对应 schema 中的 type Query
- 向下执行 query.users。所谓执行(resolve)就是执行 server 中定义的对应 schema 节点的 resolver 函数。
- 继续向下依次执行 query.users.name,query.users.posts,query.users.posts.title。
每个 schema 节点的 resolver 函数都会接收上层节点的返回值、查询输入的变量、当前上下文和一些额外信息作为参数,并返回一个符合 schema 类型定义的结果供下层节点继续执行。所有节点执行完毕后,最终的完整结果会返回给 client。
由此可见,resolver 函数的灵活性非常高,例如我们可能在 query.users 节点执行一次数据库查询得到结果,在 query.users.posts 中通过一次 HTTP 请求得到结果,在 query.users.posts.title 中从文件系统中读取结果,只要返回值符合 GraphQL schema 的定义即可。
Data Layer 的设计
Data layer 运行在浏览器内,同时我们也希望前端 UI 代码通过标准的 GraphQL API 和它进行交互,这样我们可以随时将 data layer 迁移为独立的 NodeJS 服务。因此 data layer 的设计始终需要满足:
- 只使用 JavaScript 的标准 API,不使用任何浏览器 API,保证在 NodeJS 运行时中也可以正常工作。
- UI 和 data layer 之间的通信必须是可以序列化的,而不能直接通过内存传递数据,保证远程调用的能力。
当 data layer 运行在浏览器内时,整体形态如图所示:
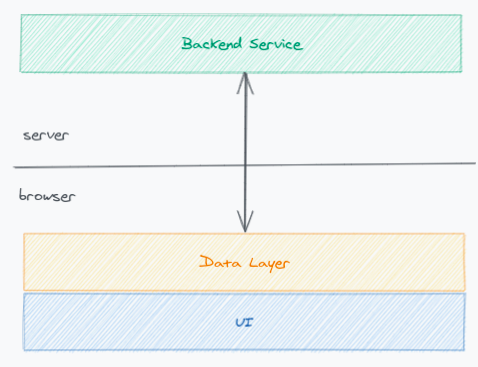
在 data layer 内每个 GraphQL 请求执行时,会在对应的 resolver 函数内发出 HTTP 请求,从已有的后端服务中获取数据。
在这样的实现下,我们已经可以让我们的前端项目获得 GraphQL 带来的各种好处,只不过在网络请求方面不会比之前的 Restful API 有数量和数据量上的节省(因为 data layer 还是会发出基本等量的请求)。
需要注意的是,即使没有网络请求上的优势,data layer 依然帮助我们的前端代码很好地解决了长久存在的数据拼接抽象、数据缓存一致性、UI 正确更新等问题,这也说明数据裁剪绝对不是 GraphQL 唯一的价值。
在我们的计划中,如果 data layer 稳定的实现完我们 UI 代码中所有的数据请求代码,我们就可以将它迁移为独立的 NodeJS 服务,变成这样的形态:
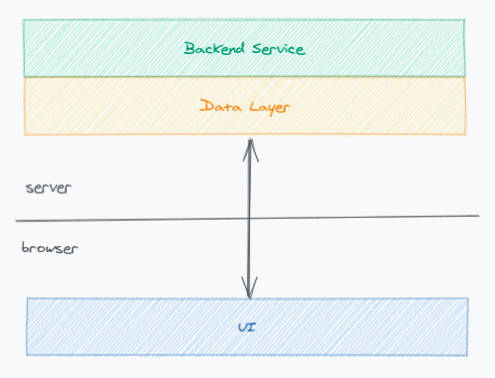
进一步获得以下收益:
- 数据裁剪,减少前后端的请求数量和数据量。
- 减少浏览器内的开销,提升用户体验。
- data layer 离数据源(后端服务)更近,整体响应时间缩短。
阵痛:意料之中的挫折
时间来到 2019 年 8 月份,GraphQL 在我们的内部系统中已经使用了半年以上,data layer 也在产品主线的前端项目中加以应用。
在这个阶段我们开始遇到一些问题,值得庆幸的是这些问题在前期调研的过程中我们已经有所了解,因此尽管解决起来不太容易,但也不至于毫无头绪。
Apollo Client 缓存管理
在上文中提到的“响应式的级联缓存”并不是我们独创的概念,GraphQL 社区中最流行的客户端 Apollo Client 就一直在深度使用这一实现。
但是在 Apollo Client v2 的实现中,这层缓存一直存在一个致命的缺陷:缺少易用的缓存失效方式。官方文档中描述的 refectch 和 write cache 等方式在项目规模稍大时就会难以维护,而在社区中相关的讨论已经持续长达两年之久,直到今天 Apollo Client v3 的 RC 版本中给出的缓存失效方案仍然不能完全解决问题。
这一问题在我们的内部系统迭代半年之后也开始出现。当时我们有两个选择:
- 等待官方承诺在 2019 年 10 月发布的 v3 版本解决这一问题。
- 在 Apollo Client 的基础上自行设计实现一个缓存失效方案。
最终我们选择花半个月的时间完整理解 Apollo Client 的代码,再经过一周的设计之后完成了一个包含依赖追踪、UI 自动响应的缓存失效方案。我们之所以可以比社区更快地解决问题,是因为:
- 我们可以不考虑向前、向后的兼容性问题,设计只为我们使用场景服务的方案。
- 我们可以在短时间内投入充足的人力,集中解决这一个问题。
从这个过程中也可以看出,使用开源社区的方案并不代表永远不能出现分岔、无限制地等待 upstream 给出方案。
事实上我们甚至没有使用一个 fork 版本的 Apollo Client,而只是在上层代码中进行了封装,使用了一些 private API 就解决了问题。
GraphQL schema 也需要设计
在应用 data layer 的过程中我们遭遇了另一个问题:怎么设计出“好用”的 GraphQL schema。
和任何一种 API 规范一样,GraphQL schema 也需要设计,而且与 RESTful API 等规范相比,GraphQL 最佳实践相关的资料还是非常少的。
在我们的 data layer 中,背后的数据源也不是非常灵活的数据库查询,而是几套比较复杂的 HTTP API。所以在实际的开发中,我们一边摸索最佳实践,一边在 schema 的易用性、请求数量、性能等方面做取舍,并且应用了相当复杂的批量处理和缓存策略进行优化,导致后期 data layer 的开发变成了一项技巧性工作。
严格来说这不是一个阻碍开发的问题,但确实限制了我们的效率。这也促使我们想在下一阶段在两方面做出改进:
- 以独立后端服务的形式运行 GraphQL 网关,最好还能够使用数据库作为数据源。
- 从成熟的项目中借鉴一套 GraphQL schema 设计的最佳实践。
把握机会,真正的 GraphQL
2019 年第四季度,在思考 data layer 的下一步方向时,我们突然获得了一个更好的机会:产品主线中会新增一个管理面产品。考虑到后端的同学需要将精力投入到其它更具挑战性的任务中,准备让前端组来负责新的管理面产品 Web 前、后端的开发。
这个机会不仅完美的贴合我们上一阶段总结出的改进方向,而且带来更大的发挥空间。在随后半年多的时间里,我们实现了:
- 用数据库缓存所需数据,以独立后端服务的形式运行 GraphQL 网关,彻底解决了 data layer 中难以避免的性能问题,显著提升了用户体验。
- 基于 Prisma ORM 封装了一套功能完整、表达能力强的 GraphQL schema,降低 API 的设计和实现成本,提升了 API 的使用体验。
- 数据库、网关、UI 全链路的类型安全,让大多数问题在编译阶段暴露。同时开发代码生成工具,让一些数据交互复杂的 UI 组件可以直接通过数据库 schema 生成。
- 后端的同学可以全情投入底层的开发工作,不再需要为 UI 设计 API,也减少了很多联调的工作。
2019 年 1 月,我们还是没有任何一名成员了解 GraphQL 的前端团队。
2020 年 5 月,我们已经是所有成员非常熟悉 GraphQL 使用、并且有 2 名成员精通 GraphQL 细节的管理产品团队。
这一过程中固然有机会和运气的作用,但如果我们从一开始就只是推动后端团队去帮助我们进行 GraphQL 改造,那么想必这一切也都不会发生。
如果你也认可我们处理工程问题的思路和方式,也欢迎加入我们。